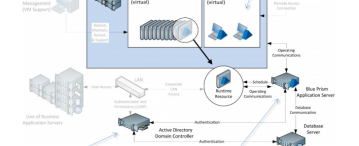
High Availability and Disaster Recovery
Where Blue Prism is running business critical automated processes, the consequence of a production environment failure preventing the successful running of these processes can be serious.
Consideration should therefore be given to:
- The creation of a Disaster Recovery environment to act as a contingency production environment.
- The procedures involved in invoking DR
- The procedures involved in returning to the Business As Usual production environment
- The frequency of testing the DR environment and associated procedures.
From a technical perspective High Availability and Disaster Recovery can be achieved by such concepts as:
- Component redundancy. Having n+1 components in your Blue Prism environment.
- Using Load Balancers across multiple Application Servers. (Note: When using multiple Application Servers each should have the same encryption key)
- Spreading Blue Prism infrastructure across multiple, geographically spread sites.
- SQL Database HA concepts such as:
- Clustering
- Always On Availability Groups
- Mirroring
- Log shipping
- Multi-site replication.
- Keeping offsite Backups
- Taking advantage of Blue Prism Resource Pools
- Resilient Process Design
- Monitoring components vigilantly.
Refer to the Customer Support Procedures for how to raise an incident with Blue Prism Customer Support